”wrapper machine-learning reinforcement-learning ai deep-learning neural-network artificial-intelligence openai dqn gym unreal-engine ue4 learning-agent UnrealEngineC “ 的搜索结果
Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems 3rd Edition Aurélien Géron (Author)
GPT-3曾经是最大、最让人惊艳也是最具争议的预训练语言模型。介绍GPT-3的论文长达72页,...与文章《》中介绍的GPT-2在Zero-shot Learning设置下的惊喜表现相比,GPT-3在Few-shot Learning设置下的性能足以震惊所有人。

最后,小维根据爸爸的提示,找到了画有斑马的卡片。同样用一个形象的例子解释:爸爸拿了五张分别画有柴犬、柯基、边牧、哈士奇和阿拉斯加的卡片,告诉小维,这些都属于犬类,然后给了小维三张卡片,分别画有橘猫、...
最好用的版本CNKI E-Learning 2.0.1,中国知网阅读器E-Learning通过科学、高效地研读和管理文献,以文献为出发点,理清知识脉络,探索未知领域,管理学习过程,实现探究式学习、终生学习。




ChatGLM-6B的P-Tuning微调详细步骤及结果验证

mastering machine learning with scikit-learn
Q-learning是一种很常用的强化学习方法,DQN则是Q-learning和神经网络的结合。 Q-learning 首先要设计状态空间s,动作空间a,以及reward。 一次transition就是(s,a,w,s_) 一次episode就是 DQN Q-...
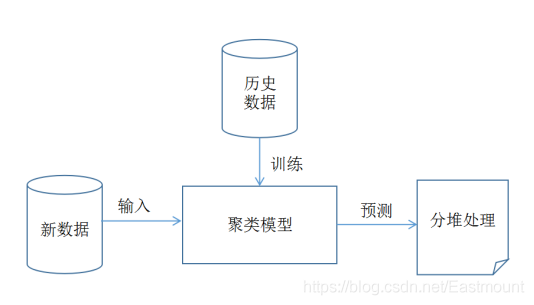
1.强化学习介绍 2.Q-Learning算法实例 3.一个Q-Learning算法的程序实现
论文地址: ...前言: Q-Learning算法由于受到大规模的动作值过估计(overestimation)而出现不稳定和效果不佳等现象的存在,而导致overestimation的主要原因来自于最大化值函...

本文主要介绍 BLIP-2


Joint Learning和Multi-Task Learning都属于集成学习(Ensemble Learning)的范畴,但网上关于Joint Learning的相关资料较少,因此在这里对这两种学习方式进行简要介绍,并对其不同点进行区分。 Joint Learning ...
强化学习在alphago中大放异彩,本文将简要介绍强化学习的一种q-learning。先从最简单的q-table下手,然后针对state过多的问题引入q-network,最后通过两个例子加深对q-learning的理解。
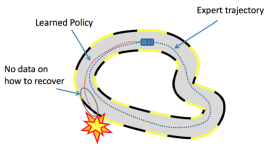

Q-Learning算法学习简介Q-Learning算法下,目标是达到目标状态(Goal State)并获取最高收益,一旦到达目标状态,最终收益保持不变。因此,目标状态又称之为吸收态。Q-Learning算法下的agent,不知道整体的环境,知道...
本文是对 http://mnemstudio.org/path-finding-q-learning-tutorial.htm 的翻译,共分两部分,第一部分为中文翻译,第二部分为英文原文。翻译时为方便读者理解,有些地方采用了意译的方式,此外,原文中有几处笔误...
推荐文章
- withRouter,非根组件获取路由参数_withrouter 只能取到路由中的一个参数-程序员宅基地
- ubuntu环境下QT5操作摄像头报错,cannot find -lpulse-mainloop-glib cannot find -lpulse cannot find -lglib-2.0_cannot find–lpulse-程序员宅基地
- 用jbpm_bpel学jwsdp的ant方式使用-程序员宅基地
- 输入数字判断星期几_html获取当前星期几-程序员宅基地
- SpringBoot整合Activiti7——实战之放假流程(会签)_activit7中会签-程序员宅基地
- 阿里云服务器收到挖矿病毒的攻击,导致基础的文件被病毒污染的问题和对应的处理解决方法-程序员宅基地
- 北京东城区空调维修办法,格力变频空调出现ph,到底是怎么回事?_格力变频空调ph代码-程序员宅基地
- vscode编辑器使用拓展插件background添加背景图片改变外观_background vscode-程序员宅基地
- android 简单打电话程序_android拨打电话的程序-程序员宅基地
- 第二届中国(泰州)国际装备高层次人才创新创业大赛_泰州市双创人才计划2022-程序员宅基地